At first I wanted to just update the original post with url_fetch extension but then decided to write a proper callback SQF implementation. Thanks to Sandbird for letting me know of some problems with url_fetch 2.0. I have already made a tiny adjustment to it. V2.1 is more reliable when it comes to multiple requests. Combined with new callback handling it should be sufficient to handle requests to different URLs.
It is now possible to call a function or a code with results of a request. You can therefore make different requests to different URLs and call different functions with results. Requests are queued and the whole request handling is done in scheduled environment. In my tests it took about 0.18 seconds per simple request, based on 100 requests connecting to a website across the globe. But again, I must stress, this is not an industrial power strength extension and no database like operations should be attempted with it.
url_fetch_error
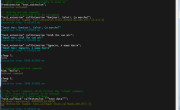
You must have this function in case something went wrong with your request. This function is called automatically in case there is an error, with the following params inside _this variable: [url, error], where url (STRING) is the URL you called and error (STRING) is the short error description. Here is my test implementation of it using debug_console extension, but feel free to make your own:
url_fetch_callback
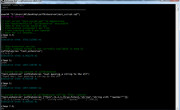
This is main function you will be using to fetch an URL. It takes following params: [url, callback], where url (STRING) is the URL you want to fetch and callback is either (CODE) the function variable containing code or bare code to spawn when result is received or (STRING) the path to the .sqf file to execVM. The function or a code will receive the following params inside _this variable: [url, result], where url (STRING) is the URL you called and result (STRING) is data returned. You might need additional call compile operation performed on the result if it needs to be anything else but STRING. Here is the code:
Examples of use
I have tested reliability and speed of the extention and SQF driver with this piece of code:
A couple of simple examples:
And if you want to execute a file:
Enjoy,
KK